メッセージコンバータとメッセージホルダー
Contents
メッセージコンバータとメッセージホルダー#
概要#
メッセージコンバータは多言語に対応したメッセージ表からゲームで使用するためのリソースを作成するためのツールです。出力されたメッセージデータはメッセージホルダーと呼ばれるMGL用のエクステンションを利用する事で、ゲーム側から簡単に扱うことが可能となります。
本項では、これらを利用してゲーム内でメッセージを扱うための方法を解説します。
ツールの導入#
メッセージ表をコンバートするにはmgl-msgconvというツールを使用します。このツールはコマンドラインツールであり、コンソール(Windowsのコマンドプロンプト、macOSのターミナル等)から利用します。
ツールの導入方法は次の通りです。
Windows#
MGLのダウンロードページにアクセスし、「ツール」からmgl-msgconvのWindows向けの実行可能バイナリをダウンロードしてください。ダウンロードしたアーカイブ内にある「mgl-msgconv.exe」がツール本体になります。このファイルを必要に応じてパスの通ったディレクトリにコピーしてください。
macOS#
macOSではHomebrewを用いて導入します。Homebrewについては次のリンク先を参照してください。
MGL関連のツールは公式パッケージとして登録されていないため、最初にtapコマンドを用いてパッケージの追加を行う必要があります。
$ brew tap AcerolaSoftware/tap
このコマンドにより、MGLの配布元が提供しているツール類をHomebrewから導入できるようになります。
tapコマンド実行後、installコマンドによりmgl-msgconvをインストールします。
$ brew install mgl-msgconv
実行後、mgl-msgconv -vと入力してバージョン情報が表示されていれば成功です。
その他の環境#
一般的なPOSIX準拠のシステムであれば、ソースコードからビルドすることで利用可能です。
mgl-msgconvはビルドに次のソフトウェアを利用します。
C++17に対応したコンパイラ(clang推奨)
SCons (バージョン4.0.0以降)
ビルド方法は次の通りです。
$ scons
正常にビルドが完了した場合、そのディレクトリにmgl-msgconvが生成されます。
メッセージ表の作成#
メッセージコンバータを使用する前に、まずは変換元となるメッセージ表をCSV形式のテーブルとして作成する必要があります。このCSVファイルはRFC 4180に準拠し、UTF-8エンコーディングである必要があります。多くのソフトウェアでは、区切り文字に',' (0x2C)を、改行コードにCR+LFを指定することでRFC 4180に準拠した出力結果になります。
注釈
ここではCSVファイルの内容をテキストで解説しますが、実際の開発ではいずれかのソフトウェアを経由して編集する事を推奨します。mgl-msgconvはApple NumbersおよびCSV+を用いて動作確認を行なっています。
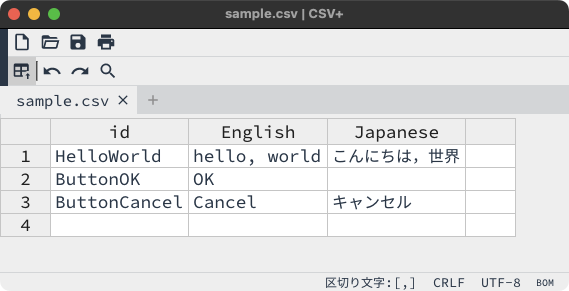
CSV+でのサンプルの記述例#
最初のレコード(行)には言語名を設定します。フィールド(列)の最初にはidと記述し、以降にサポートする言語名を入力します。このとき、最初に記述した言語名(フィールドの2番目)がデフォルトの言語となります。
例として、英語をデフォルトに設定し、日本語にも対応させる場合は次の通りです。
id,English,Japanese
記述する言語名は任意ですが、MGL向けのエクステンションを利用する場合、特定の名前を使用することでMGL::System::Localeに設定されている言語を参照して自動認識するようになります。名前と言語の対応関係については言語名と言語の対応表を参照してください。
2行目以降のレコードには具体的なメッセージの内容を記述します。最初のフィールドにはそのメッセージを表す一意のメッセージIDを、以降のフィールドには最初のレコードに定義した順の言語でメッセージ内容を記述します。
HelloWorld,"hello, world","こんにちは、世界"
mgl-msgconvは言語名とメッセージIDをプログラム側で扱うための識別子として出力する機能を持っています、したがって、これらの命名規則はC/C++の識別子の命名規則に準じたものを推奨します。
メッセージを省略した場合はデフォルトの言語に設定したものがそのまま使用されます。
ButtonOK,OK,
ButtonCancel,Cancel,キャンセル
この例ではButtonOKの日本語メッセージを記述していないため、日本語でも英語のOKが使用されます。
メッセージ表の変換#
メッセージコンバータはソースコード出力とバイナリ出力の2通りの出力方法があります。また、バイナリ出力の際にインデックス化を指定することで、メッセージデータを最適化する機能も備えています。
本項ではこれら3通りの方法について解説します。
ソースコード出力#
ソースコード出力はメッセージデータをCまたはC++のソースコードで扱える形式で出力します。メッセージデータの規模が小さく、実行ファイルのサイズに大きな影響を与えない場合に有効な出力方法です。
ソースコード出力を行うには、--sourceオプションを使用します。
$ mgl-msgconv sample.csv --source
メッセージIDリストを出力: ./msg_id.inc
メッセージテーブルを出力: ./msg_english.inc
メッセージテーブルを出力: ./msg_japanese.inc
成功。
変換結果は各言語ごとのメッセージデータとメッセージIDのリストが拡張子.incのテキスト形式で出力されます。この場合、"msg_id.inc"にはメッセージIDのリストが、"msg_english.inc"と"msg_japanese.inc"にはそれぞれの言語のメッセージが出力されています。
各言語の文字列テーブルのファイル名には、CSVで指定した言語名を小文字化したものが使用されます。接頭語のmsgの部分は--prefixオプションで変更できます。
出力された各ファイルはC/C++のソースコードに埋め込んで使用することを想定しています。C++でこれらを扱うための例を次に示します。
//! メッセージID
enum class MessageID
{
#include "msg_id.inc"
};
//! 英語メッセージテーブル
constexpr const char *kEnglishMessageTable[]
{
#include "msg_english.inc"
};
//! 日本語メッセージテーブル
constexpr const char *kJapaneseMessageTable[]
{
#include "msg_english.inc"
};
//! メッセージテーブルの要素数
constexpr size_t kMessageTableSize = sizeof(kEnglishMessageTable) / sizeof(const char *);
/* ------------------------------------------------------------------------- */
/*!
* \brief 言語に対応したメッセージを取得
* \param[in] messageID メッセージID
* \return 対応したメッセージ。引数が不正な場合はnullptr
*/
/* ------------------------------------------------------------------------- */
const char *GetMessage(MessageID messageID) noexcept
{
// インデックスのサイズオーバーチェック
auto index = static_cast<size_t>(messageID);
if (index > kMessageTableSize)
{
return nullptr;
}
// 言語設定による分岐
switch (MGL::System::Locale().GetLanguage())
{
// 言語設定が日本語であれば日本語メッセージを返す
case MGL::System::Language::Japanese:
return kJapaneseMessageTable[index];
/*
* 他の言語にも対応するならここに追記する
*/
// デフォルトでは英語メッセージを返す
case MGL::System::Language::English:
default:
return kEnglishMessageTable[index];
}
}
ここでは#includeディレクティブを使用したテーブルの挿入を行っていますが、ツールにソースコードそのものを生成させたい場合は--replaceオプションによるテキスト置換機能が利用可能です。詳細はテキスト置換にて解説します。
バイナリ出力#
バイナリ出力ではメッセージデータをバイナリデータで出力します。プログラム側でこのデータを扱うためにはバイナリデータを読み込んで解析する必要があり、MGLではこのバイナリデータを扱うためのエクステンションを用意してあります。
MGLではデフォルトの出力方法がバイナリ出力となっています。したがって、次のように単にCSVファイルを与えるだけでバイナリデータが生成されます。
$ mgl-msgconv sample.csv
ハッシュのシード値: 0xA3F6C23E
バイナリファイルを出力: ./msg.bin
メッセージIDリストを出力: ./msg_id_hash.inc
言語名リストを出力: ./msg_lang_hash.inc
成功。
出力される"msg.bin"がメッセージデータの格納されたバイナリファイルになります。
バイナリファイルはハッシュ化されたメッセージIDと言語名をキーとしてメッセージを特定します。"msg_id_hash.inc"と"msg_lang_hash.incはそれぞれメッセージIDと言語名のハッシュ値の定義であり、次のように使用することを想定しています。
//! 言語名
enum class LanguageID : uint32_t
{
#include "msg_lang_hash.inc"
};
//! メッセージID
enum class MessageID : uint32_t
{
#include "msg_id_hash.inc"
};
もしハッシュ値が衝突する場合は変換失敗となります。その場合は--hash-seedオプションを用いてシード値を変更してください。
MGLにおけるバイナリファイルの利用方法はメッセージホルダーの利用を参照してください。エクステンションを用いず独自に解析して使用する場合、バイナリフォーマットの情報を参照してください。
注釈
バイナリ出力もソースコード出力と同様に、.incファイルの出力の代わりに--replaceオプションによるテキスト置換が利用可能です。後述するMGL向けのエクステンションはテキスト置換を利用するため、.incファイルは使用しません。
インデックス化してバイナリ出力#
--indexingまたは--indexing-allオプションを指定してバイナリ出力を行うことで、メッセージの各文字をインデックス化して出力することも可能です。この機能はゲーム中の文字描画の負荷を軽減するための最適化機能となります。
インデックス化の指定によりメッセージコンバータは使用文字リストを作成し、各文字はこのリストへのインデックスに変換されます。この使用文字リストをラスタライズフォント生成ツールに与えることで、これに対応したリソースの生成が可能です。
インデックス化されたメッセージは描画時にグリフ情報を検索する必要がなく、テキスト整形やタグの解析もコンバート時に行われるため、文字描画にかかるCPU側のコストを必要最小限に抑えられます。反面、そのメッセージの描画は、同時に出力される使用文字リストを用いて生成したフォントリソースのみに限定されます。どちらが最適であるかは作るゲームによって異なるため、これらの性質を鑑みたうえで導入を検討してください。
ヒント
後述のメッセージホルダーはインデックス化による差異を吸収するため、どちらを選択してもアプリケーション側での扱い方に変化はありません。
インデックス化してバイナリデータを出力するには、--indexingまたは--indexing-allオプションを指定します。
$ mgl-msgconv sample.csv --indexing font_metrics.bin
--indexingを指定した場合、インデックス化は言語ごとに行われ、使用文字リストも言語ごとに出力されます。--indexing-allを指定した場合は全ての言語をまとめてインデックス化し、使用文字リストは1つだけ出力されます。言語ごとにフォントリソースを用意する場合は--indexingを、全ての言語を1つのフォントリソースにまとめる場合は--indexing-allを使用してください。
変換に成功した場合、"msg_using_[言語ID].json"の名前で使用文字リストが出力されます。--indexing-allを指定した場合は言語IDの代わりにallが使用されます。また、先頭のmsgの部分は--prefixオプションにて変更可能です。
出力された使用文字リストはラスタライズフォント生成ツールのUsingCharacterListパラメータに指定してください。この指定により、インデックス化されたメッセージに対応したフォントリソースが生成されます。
メッセージホルダーの利用#
メッセージホルダーはメッセージコンバータが出力するバイナリデータを扱うためのMGL向けエクステンションです。バイナリデータの解析と使用言語の管理、メッセージIDのハッシュ値から該当するメッセージを取得する機能を提供します。
ここでは、導入方法の各プラットフォーム共通で示した例のディレクトリ構成に追加することを想定します。異なるディレクトリ構成を使用する場合は適宜置き換えてください。
ライセンス#
メッセージホルダーはMGL本体と同じzlibライセンスに基づいて配布されています。もしMGLと併用する場合、メッセージホルダーはMGLの一部として扱って問題ありません。zlibライセンスの詳細はMGLのライセンスを参照してください。
アーカイブ内のreplace_template_sample以下にあるソースコードは、著作権を可能な限り放棄したCC0 1.0に基づいて配布されています。これらは改変も含め制限なく利用可能です。
ダウンロードとコピー#
メッセージホルダーはソースコードとして配布しています。まずはMGLのダウンロードページの「エクステンション」からmglext-message-holderをダウンロードしてください。
アーカイブの内容は次のような構成になっています。
.
├── LICENSE.txt
├── mglext
│ ├── message_holder.cc
│ └── message_holder.h
└── replace_template_sample
├── LICENSE.txt
└── message.h
mglext内のソースとヘッダがメッセージホルダークラスです。このディレクトリの内容をプロジェクトのsrc/mglextに配置するようにコピーし、プロジェクトに追加してください。結果、次のような構成になることを想定します。
src
├── app_main.cc
├── app_main.h
└── mglext
├── message_holder.cc
└── message_holder.h
この状態でビルドし、エラーが発生していなければメッセージホルダーの導入は成功です。
コンバート#
コンバート方法そのものは通常のバイナリ出力と同様ですが、アーカイブ内にはメッセージへのアクセスを簡易化するためのヘッダが含まれています。このヘッダを置換テキストとしてコンバータに渡すことで、より簡単にメッセージへのアクセスが可能となります。
アーカイブ内のreplace_template_sample内にあるmessage.hがヘッダの置換テンプレートです。まずはこのファイルを開き、名前空間AppNameを任意のものに変更してください。
ここでは例として、次のようにresourceディレクトリ下にmessageディレクトリを作成し、ここにメッセージデータ関連を保管することにします。
resource
└── message
├── message.csv
└── message.h
コンバータは--outputオプションを用いることでファイルの出力先ファイルを指定できます。ここでは、workdirディレクトリへの出力を想定します。
これらを踏まえたうえでのコンバート方法は次の通りです。
$ cd resource/message
$ mgl-msgconv message.csv --output ../../workdir --replace message.h
もしインデックス化による最適化を行う場合は、追加で--indexingまたは--indexing-allオプションを使用してください。
実行後、次のようなファイル構成になっていれば成功です。Xcodeを使用する場合、msg.binをプロジェクトに追加することも忘れないでください。
.
├── resource
│ └── message
│ ├── message.csv ←メッセージデータのCSVファイル
│ └── message.h ←ヘッダの置換テンプレート
├── src
│ ├── app_main.cc
│ ├── app_main.h
│ ├── message.h ←置換後のヘッダ
│ └── mglext
│ ├── message_holder.cc ←メッセージホルダーのソース
│ └── message_holder.h ←メッセージホルダーのヘッダ
└── workdir
└── msg.bin ←メッセージのバイナリデータ
注釈
ディレクトリ構成を変更する場合は、置換元のヘッダファイルの最初の行に記述されているOUTPUT_NAMEを変更してください。この置換コマンドは置換後のファイル名を指定するもので、--outputで指定した出力先からの相対パスでの指定になります。
メッセージデータの読み込み#
メッセージホルダーにメッセージデータを読み込ませる例を次に示します。この処理をアプリケーション初期化時(AppDelegate::Initialize()など)に記述してください。
#include "mglext/message_holder.h"
...
auto &messageHolder = MGLExt::MessageHolder::CreateInstance();
if (!messageHolder.Load("$resource/msg.bin"))
{
// 読み込み失敗
}
言語名に言語名と言語の対応表で定義された名前を使用している場合、読み込み時点でMGL::System::Localeに設定されている言語を自動で選択して使用します。また、MGL::System::Locale::SetLanguageにてMGLの言語設定を変更した場合、メッセージホルダーはそれを検知して自動で使用言語を変更します。
メッセージの取得方法#
アプリケーション側からメッセージを取得するには、メッセージホルダーを直接使用せずにテキスト置換によって出力されたヘッダファイルを用います。まずはこのヘッダをインクルードしてください。
#include "message.h"
このヘッダには、各メッセージIDのハッシュ値と、メッセージにアクセスするためのラッパークラスMessageが定義されています。
Messageクラスはコンストラクタの引数にMessageIDを渡すことで、そのメッセージ内容をUTF-8またはインデックス文字列で取得できるようになります。どちらの形式で取得できるかは、コンバート時のインデックス化の指定の有無により自動で決定します。
Message message(MessageID::HelloWorld);
// コンバート方法によってUTF-8またはインデックス文字列に暗黙的に変換可能
// (この場合はUTF-8エンコーディング)
const char *string = message;
MGL::Render::Font::PrintはUTF-8とインデックス文字列のどちらにも対応しているため、コンバート方法に関わらずMessageクラスをそのまま渡せます。
MGL::Render::Font font(kFontKey);
if (font)
{
font.Print(Message(MessageID::HelloWorld));
}
テキスト置換#
既に何度か言及している通り、コンバータは.incファイルを出力する代わりに、既存のテキストの一部をこの出力結果で置き換える置換機能を備えています。この機能を利用することにより、#includeディレクティブを用いずにソースコードそのものを出力させることが可能です。
テキスト置換は置換元のテキストに置換コマンドを記述し、そのファイルを--replaceオプションに渡すことによって実行します。
$ mgl-msgconv message.csv --replace replacing_text
置換コマンドのフォーマット#
置換元のテキストに$で囲まれた文字列を記述することで、コンバータはその文字列を置換コマンドとして認識します。
$REPLACE_COMMAND$
置換コマンドを:で区切ることによって、それ以降の文字列はコマンドの引数として扱われます。
$REPLACE_COMMAND:argument$
置換コマンドは行の先頭に書かなければならず、スペースとタブ以外の文字が先に記述されている場合は置換コマンドとして認識されません。コマンド前のインデントは結果に反映されます。置換は行単位で行われるため、その置換コマンド以降から改行までの文字列は全て無視されます。
置換コマンド#
- ID_LIST
その行にメッセージIDのリストを出力します。ソースコード出力の場合は
MESSAGE_LISTによる出力と同じ順で、バイナリ出力の場合はバイナリファイルが保持するハッシュ値の定義として出力します。- LANGUAGE_LIST
その行に言語名のリストを出力します。
出力順はCSVの最初のレコードに記述したフィールドの順です。
- MESSAGE_LIST:language
引数で指定した言語のメッセージリストをその行に出力します。このコマンドはソースコード出力でのみ使用可能です。
出力順はCSVに記述した順です。
- IF:condition
その行にCプリプロセッサの
#ifディレクティブを出力します。引数には条件を指定し、出力時に
0または1に置き換えられます。有効な引数は後述の条件の節を参照してください。- ELIF:condition
その行にCプリプロセッサの
#elifディレクティブを出力します。引数には条件を指定し、出力時に
0または1に置き換えられます。有効な引数は後述の条件の節を参照してください。- ELSE
その行にCプリプロセッサの
#elseディレクティブを出力します。- ENDIF
その行にCプリプロセッサの
#endifディレクティブを出力します。- OUTPUT_NAME:name
置換後のファイルの名前を指定します。
nameに相対パスを指定した場合、--outputオプションに指定したパスを起点とします。このコマンドを使用しなかった場合は入力ファイル名と同じ名前が使用されます。入力ファイルと出力ファイルが等価である場合、名前の末尾に
".replaced"を付与して上書きを防ぎます。
条件#
IFコマンドおよびELIFコマンドに指定可能な引数は次の通りです。
- SOURCE
ソースコード出力の場合に
1を、そうでなければ0を出力します。- BINARY
バイナリ出力の場合に
1を、そうでなければ0を出力します。- INDEXED
--indexingまたは--indexing-allオプションを使用してインデックス文字列を出力する場合に1を、そうでなければ0を出力します。- TRUE
常に
1を出力します。- FALSE
常に
0を出力します。
mgl-msgconvのオプション一覧#
- --hash-seed
バイナリ出力時に使用するハッシュ生成関数のシード値を指定します。指定しなかった場合は
0xA3F6C23E( MGL::Hash::kFNV1aDefaultValue32 )が使用されます。ハッシュ値が衝突を起こす場合はこのオプションを使用してシード値を変更してください。
- --help
簡易ヘルプを表示して終了します。
- --indexing
各言語ごとにメッセージをインデックス化して出力します。同時に、Unicodeエンコーディングの文字との変換を解決するための使用文字リストをJSON形式で出力します。
使用文字リストの出力ファイル名は
[プリフィックス]_using_[言語ID].jsonです。--sourceオプションが指定されている場合、このオプションは無視されます。- --indexing-all
全ての言語のメッセージをまとめてインデックス化して出力します。同時に、Unicodeエンコーディングの文字との変換を解決するための使用文字リストをJSON形式で出力します。
使用文字リストの出力ファイル名は
[プリフィックス]_using_all.jsonです。--sourceオプションが指定されている場合、このオプションは無視されます。- --output, -o
出力ディレクトリを指定します。指定しなかった場合はカレントディレクトリに出力します。
- --prefix, -p
出力ファイルのプリフィックスを指定します。指定しなかった場合は
"msg"が使用されます。- --replace
既存のファイルの一部をコンバート結果で置換して出力します。置換元ファイル内に置換コマンドを記述することで、その部分が変換結果に置き換えられます。
このオプションを指定した場合、各種
".inc"ファイルは出力されなくなります。置換コマンドの詳細についてはテキスト置換を参照してください。
- --source, -s
変換結果をCまたはC++で利用可能な文字列で出力します。このオプションを使用した場合、バイナリデータとその関連ファイルは出力されません。
出力ファイルは言語ごとの文字列テーブルをプリフィックス+言語名+
".inc"の名前で、メッセージIDをプリフィックス+"_id.inc"の名前で出力します。- --version, -v
バージョン情報を表示して終了します。
言語名と言語の対応表#
メッセージホルダーは言語名に特定の名前を使用することでMGL::System::Localeに設定した言語と連動するようになります。言語名と言語の対応は次の通りです。
言語名 |
言語 |
|---|---|
Arabic |
アラビア語 |
BrazilPortuguese |
ブラジルポルトガル語 |
Bulgarian |
ブルガリア語 |
Czech |
チェコ語 |
Dansk |
デンマーク語 |
Deutsch |
ドイツ語 |
English |
英語 |
French |
フランス語 |
Greek |
ギリシャ語 |
Italiano |
イタリア語 |
Japanese |
日本語 |
Korean |
韓国語 |
LatinAmericaSpanish |
ラテンアメリカのスペイン語 |
Magyar |
ハンガリー語 |
Nederlands |
オランダ語 |
Norsk |
ノルウェー語 |
Polski |
ポーランド語 |
Portuguese |
ポルトガル語 |
Romanian |
ルーマニア語 |
Russian |
ロシア語 |
SimplifiedChinese |
簡体中文 |
Spanish |
スペイン語 |
Suomi |
フィンランド語 |
Svenska |
スウェーデン語 |
Thai |
タイ語 |
TraditionalChinese |
繁体中文 |
Turkish |
トルコ語 |
Ukrainian |
ウクライナ語 |
Vietnamese |
ベトナム語 |
バイナリフォーマット#
コンバータが出力するバイナリデータには、次の順で内容が格納されています。
ヘッダ
言語テーブル
メッセージIDのハッシュテーブル
オフセットプール
メッセージプール
フッタ
全ての値のバイトオーダーはリトルエンディアンです。
ヘッダ#
ヘッダは合計24バイトで、次のパラメータが格納されています。
- +0 hashSeed (4バイト)
このファイルが使用するハッシュ計算のシード値です。
--hash-seedオプションで指定した値がこの領域に格納されます。- +4 identifier (4バイト)
このファイルがメッセージデータである事を確認するための識別子で、
hashSeedを用いて文字列"MessageData"をハッシュ化した値が格納されています。この領域はこのファイルがメッセージデータであることを確認すると同時に、ハッシュ生成アルゴリズムが意図した値を算出するかのチェックも兼ねています。ハッシュアルゴリズムの詳細についてはハッシュアルゴリズムの節を参照してください。
- +8 revision (4バイト)
このバイナリフォーマットのリビジョン情報です。現在は常に
0であり、将来フォーマットの変更が行われた場合に加算される予定です。- +12 languageCount (4バイト)
メッセージデータに収録されている言語数です。
- +16 identifierCount (4バイト)
メッセージデータに収録されているメッセージIDの数です。
- +20 flags (4バイト)
メッセージデータの属性を表すビットフラグです。内容は後述するヘッダのビットフラグを参照してください。
ヘッダのビットフラグ#
- 0ビット: インデックス文字列フラグ
メッセージプールに格納されている文字列がインデックス文字列であるかを表すフラグです。このフラグが
0である場合、メッセージデータはUTF-8でエンコーディングされています。- 1ビットから31ビット: 未使用
この領域は現在使用されていません。
言語テーブル#
言語テーブルにはCSVで指定した言語名の32ビットハッシュ値が格納されています。合計サイズは言語数x4バイトです。
このテーブルは与えられた言語からインデックスを導出する際に使用します。
メッセージIDのハッシュテーブル#
メッセージIDのハッシュテーブルには、CSVで指定した各IDの名前を32ビットのハッシュ値に変換した値が格納されています。合計サイズはメッセージIDの数x4バイトです。
このテーブルは与えられたメッセージIDからインデックスを導出する際に使用します。
オフセットプール#
オフセットプールは言語とメッセージIDからメッセージの格納先を導出するための値が格納されています。最初の4バイトにプールサイズがバイト数で格納されており、その次からプールサイズ分の領域がオフセットプールとなります。
オフセットプールはメッセージプール上のオフセット値が4バイト単位で格納された配列です。言語とメッセージIDからオフセット値を得るためには、次の方法で算出されたインデックスの要素を読み取ります。
オフセット値 = メッセージIDのインデックス * 言語数 + 言語のインデックス
このインデックスから読み取った要素はメッセージプールのインデックスとして使用します。
メッセージプール#
メッセージプールはメッセージデータを格納している領域です。最初の4バイトにプールサイズがバイト数で格納されており、その次からプールサイズ分の領域がメッセージプールとなります。
オフセットプールから読み取った要素をインデックスとしてアクセスすることによって、言語とメッセージIDに対応したメッセージデータの先頭が取得できます。
メッセージプールの要素1つあたりのサイズはエンコーディングによって異なります。メッセージがUTF-8で格納されている場合は1バイトであり、インデックス文字列の場合は2バイトです。
各メッセージは終端記号によって終端されています。終端記号はUTF-8の場合は0x00であり、インデックス文字列の場合は0xFFFFです。
フッタ#
フッタは4バイトで、文字列"EndOfRecord"をハッシュ化した32ビット値が格納されています。全ての要素を読み込んだ後にこの値が読み取れない場合、メッセージデータのパースに失敗している可能性があります。
ハッシュアルゴリズム#
mgl-msgconvが出力するバイナリファイルを扱うには、MGL::Hash::FNV1aと等価のハッシュアルゴリズムが必要です。このアルゴリズムのC++での実装例を次に示します。
constexpr uint32_t kFNV1aPrime32 = 0x1000193;
constexpr uint32_t FNV1a(const char *str, const uint32_t seed) noexcept
{
if (str[0] == '\0')
{
return seed;
}
return FNV1a(&str[1], (seed ^ uint32_t(str[0])) * kFNV1aPrime32);
}